
「サーバーレスパターンを元にAWS CDKでデータ基盤を構築する」というタイトルでClassmethod Odysseyに登壇しました #cm_odyssey
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部の笠原です。
Classmethod Odyssey Onlineにて、「サーバーレスパターンを元にAWS CDKでデータ基盤を構築する」というタイトルで発表しました。
スライド資料
動画
サンプルコード
今回は3つのサンプルスタックのコードをGitHubで公開しています。
概要
現在AWS CDKやAWS SAMを使って、サーバーレスなデータ基盤構築を行っています。
アーキテクチャを検討する際は、サーバーレスパターンを参考に構築しており、
参考となるテンプレートのコードを用意して検証や実装を進めています。
今回は3つのスタックを用意しましたので、CDKでのサーバーレスデータ基盤構築の参考にしていただければと思います。
サンプルコードを元にデプロイする際は、以下のようにスタック名を指定して実行してください。
npx cdk deploy SimpleS3DataProcessingStack
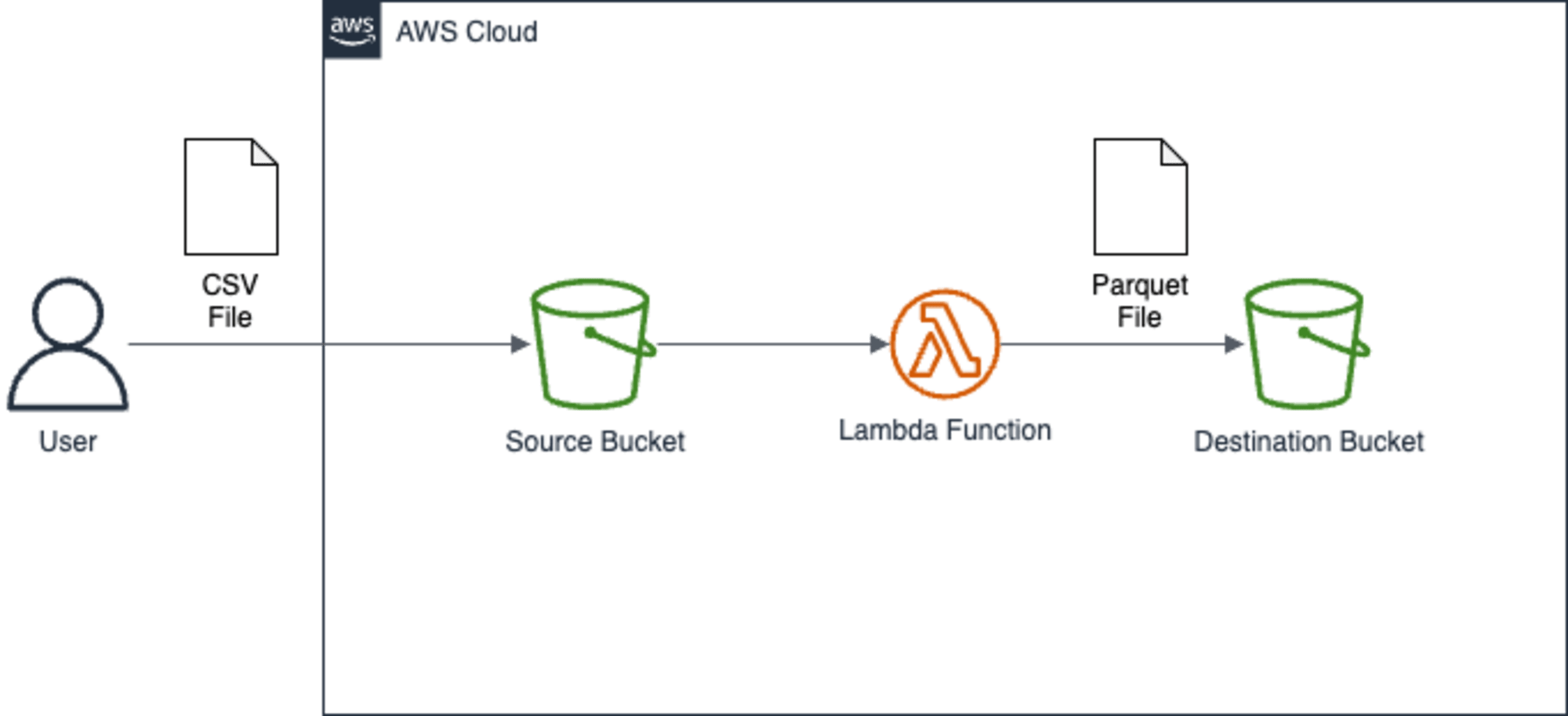
サンプルスタック1: SimpleS3DataProcessingStack
S3バケットにCSVファイルを配置したら、Lambdaが起動して、別のS3バケットにParquetファイルを配置する処理です。
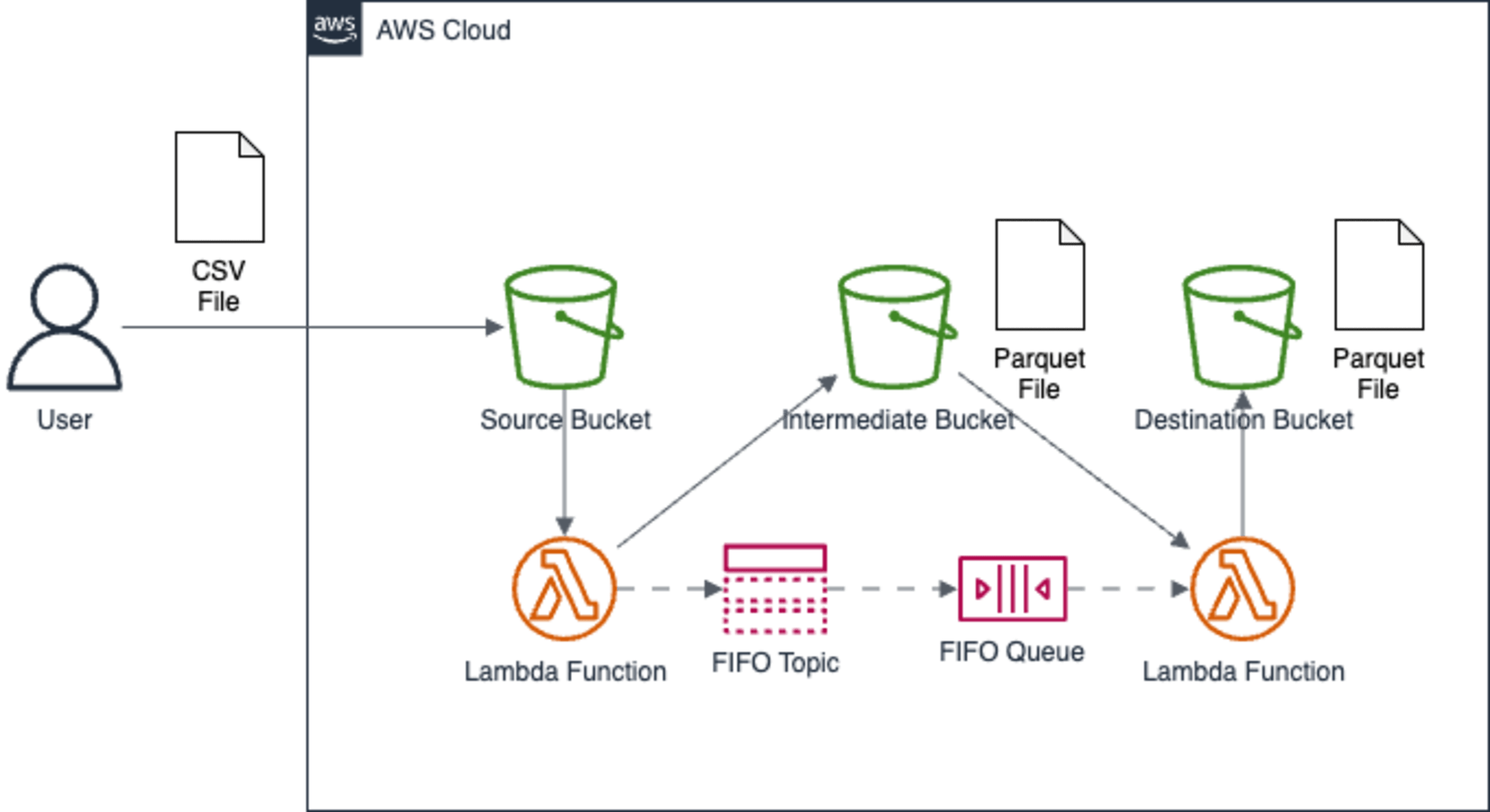
サンプルスタック2: EventDrivenCollaborationStack
サンプルスタック1の応用編です。
S3バケットにCSVファイルを配置したら、Lambdaが起動して、別のS3バケットにParquetファイルを配置する処理と、Parquetファイルの1つのカラムの型を変更する処理を行います。
Lambda間はSNS FIFOトピックとSQS FIFOキューで繋いでいます。
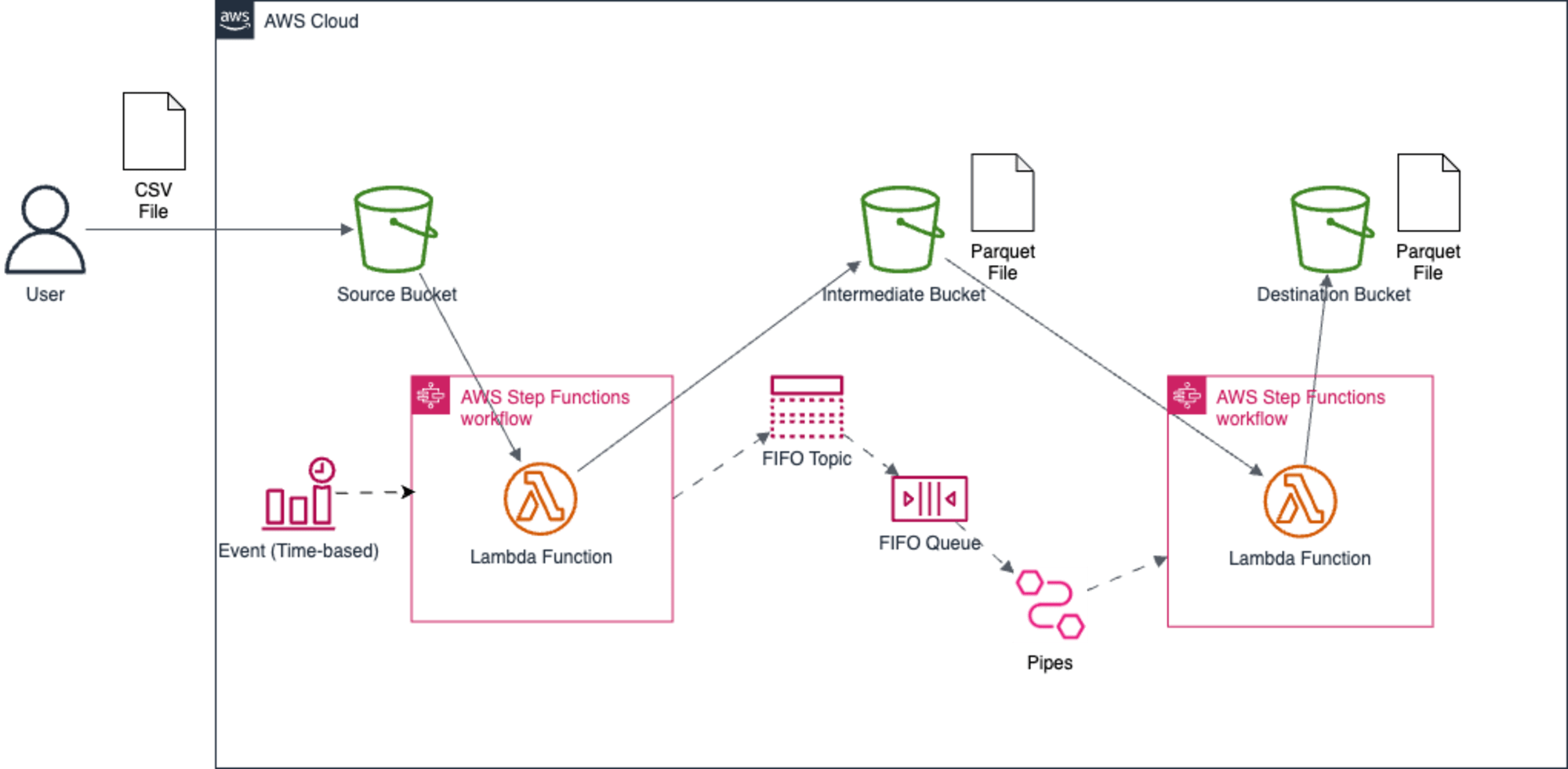
サンプルスタック3: StateMachineChainStack
サンプルスタック2をさらに応用します。
処理内容は変わらないですが、各処理はStep Functionsのステートマシンで制御し、ステートマシンからLambda関数を呼び出します。
ステートマシン間はSNS FIFOトピックとSQS FIFOキューで繋いでいます。
SQS FIFOキューのポーリングは、Lambda関数ではなくEventBridge Pipesで行い、取得したメッセージを後続のステートマシンに渡して起動してます。
考慮事項
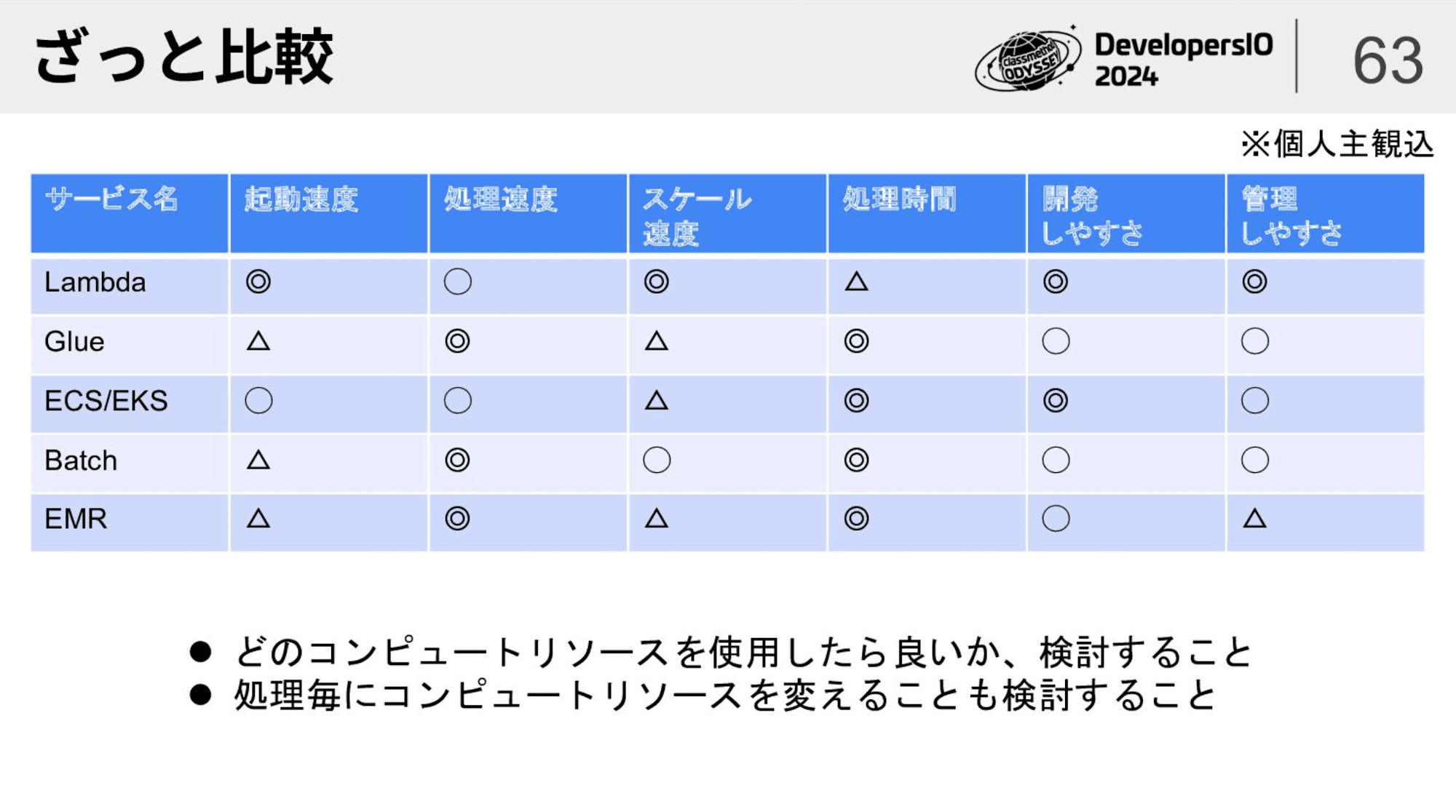
サーバーレスなデータ基盤を構築する上での考慮事項をいくつか示しました。
コンピュートリソースは、処理するデータに応じてLambda、Glue、ECS等を適切に選択して構築すると良いでしょう。
また、現在我々のチームでは、インフラのコードとアプリのコードを分けて構築しています。インフラとアプリのコードは分けないのがベストプラクティスではありますが、現状は分けた方が都合が良いケースがほとんどなので、分けております。
この辺りは、CDKの知見がもっと増えた際に改めて見直していこうと思っています。

まとめ
今回の内容を元に、サーバーレスパターンを元にCDKでデータ基盤構築する際の参考になれば幸いです。
パターンのポイントは「処理間をどう繋いでいくか」が大事だと思っています。
繋ぎ方はいろいろあるので、適切な方法で接続してサーバーレスパターンを使いこなしていきましょう。









